Lejdi Prifti

-
Residence:
Albania -
City:
Tirana -
Email:
info@lejdiprifti.com
English
Italian
French
Spring
React & Angular
Machine Learning
Docker & Kubernetes
AWS & Cloud
Team Player
Communication
Time Management
- Java, JavaScript, Python
- AWS, Kubernetes, Azure
- Bootstrap, Materialize
- Css, Sass, Less
- Blockchain, Ethereum, Solidity
- React, React Native, Flutter
- GIT knowledge
- Machine Learning, Deep Learning

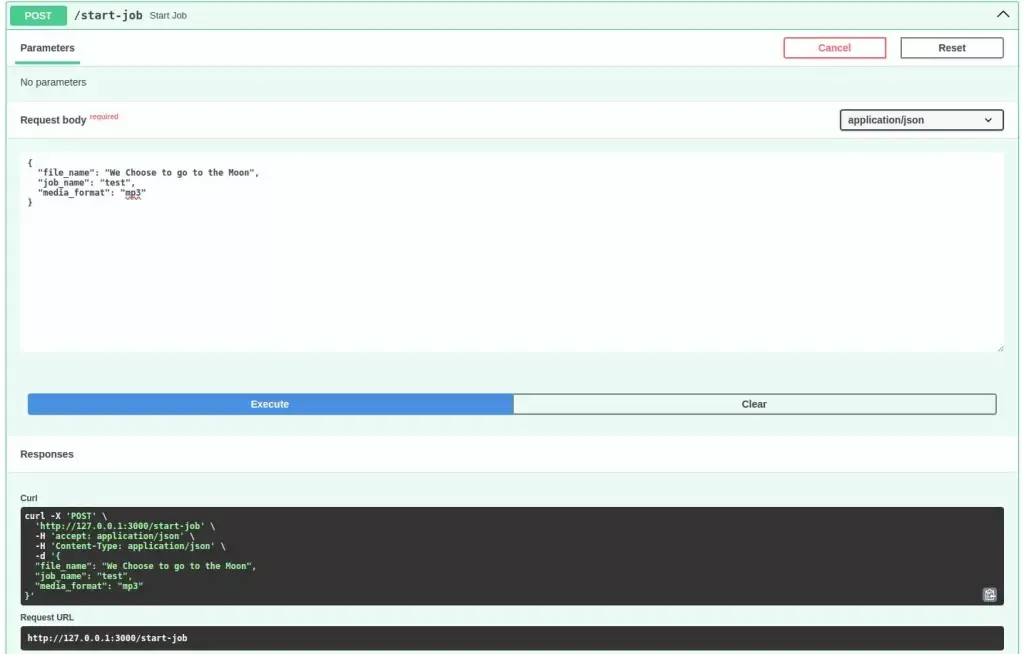

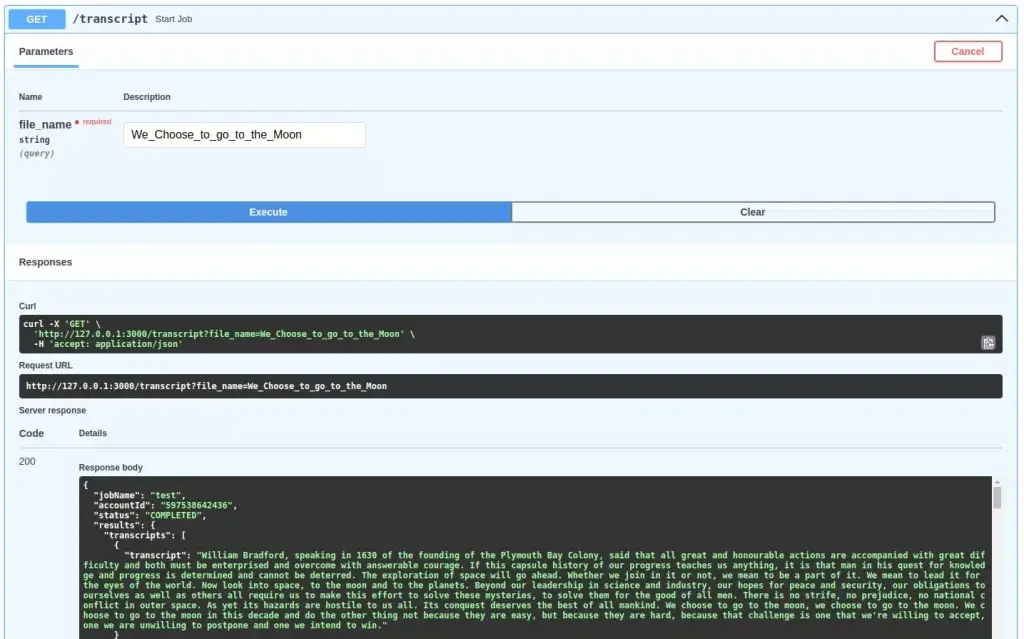

[…] this article, we will add a new feature and continue developing the program we started in the last article. You guessed it right. It is real-time streaming with AWS Transcribe and […]
[…] audio to text by leveraging AWS services, such as Transcribe and Simple Storage Service (S3). Quick tutorial to AWS Transcribe with Python writes about the batch mode of audio transcription with AWS Transcribe and S3, while Real-time […]